A comprehensive testing framework for evaluating Large Language Models' ability to generate HTML/CSS code from visual inputs, featuring automated metrics and manual evaluation across multiple leading LLMs including GPT-4, Claude, and Gemini.
This project addresses the growing need for standardized evaluation of Large Language Models (LLMs) in web development tasks. By developing an automated testing framework, we assess how accurately different LLMs can convert webpage screenshots and wireframes into functional HTML/CSS code, providing quantitative insights into model performance and reliability.

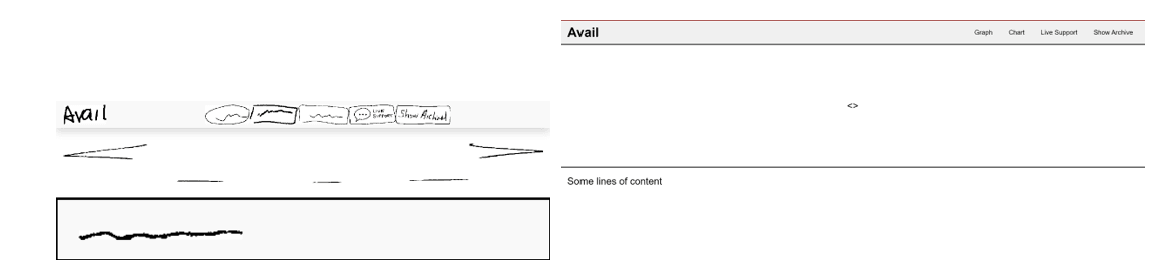

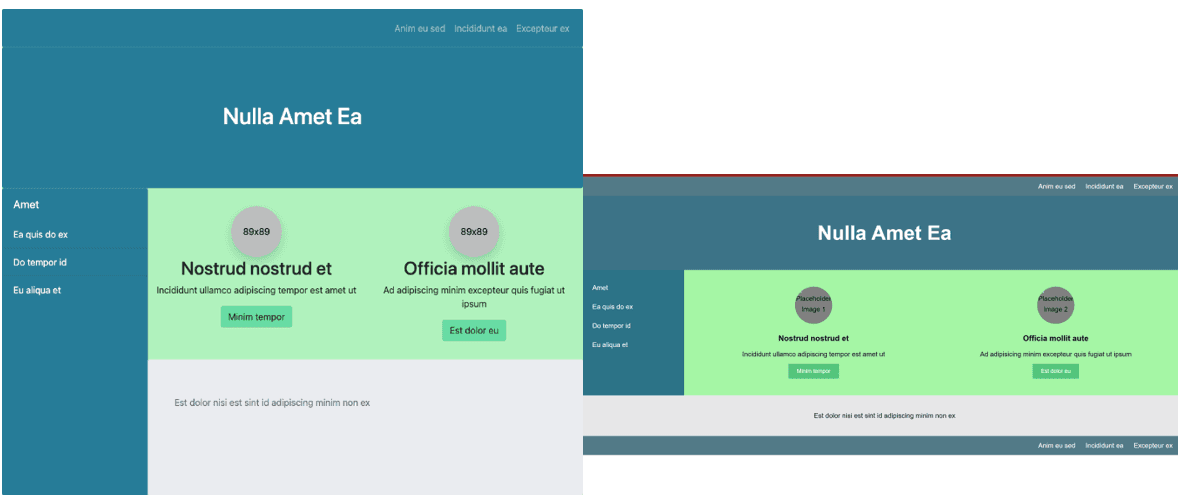
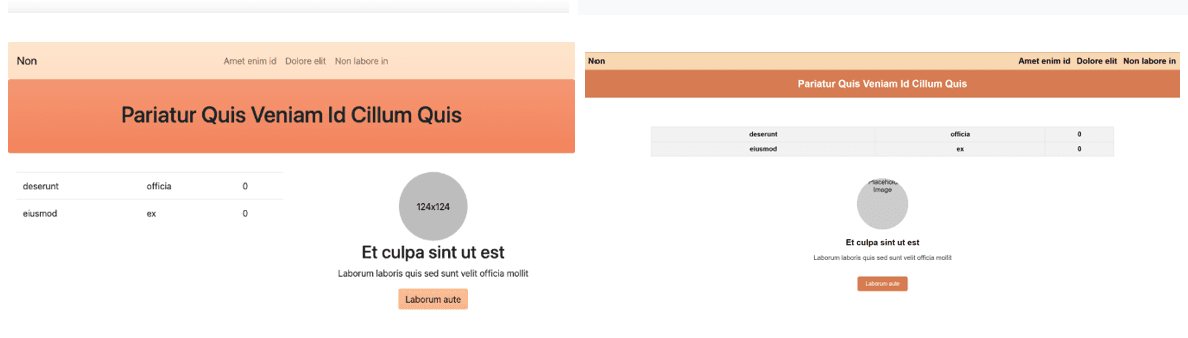
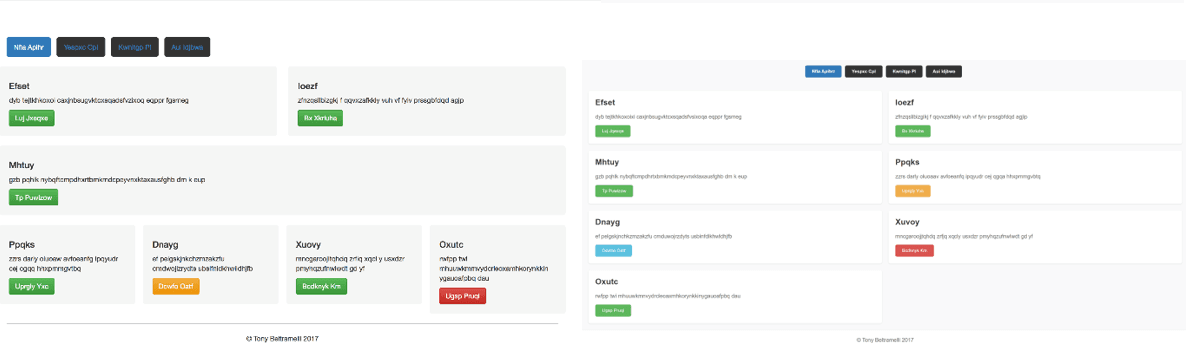
Technical Implementation
- •Developed automated testing pipeline using Python, Selenium, and multiple evaluation metrics
- •Integrated multiple LLM APIs including OpenAI GPT-4, Anthropic Claude, and Google Gemini
- •Implemented image processing using PIL and OpenCV for screenshot comparison
- •Created custom metrics including SSIM, CLIP Score, and PixelMatch for visual comparison
- •Built HTML validation system to ensure web standards compliance and accessibility
Data Processing & Evaluation
- •Processed four major datasets: WebUI2Code, Pix2Code, Bootstrap Synthetic, and Bootstrap Sketch
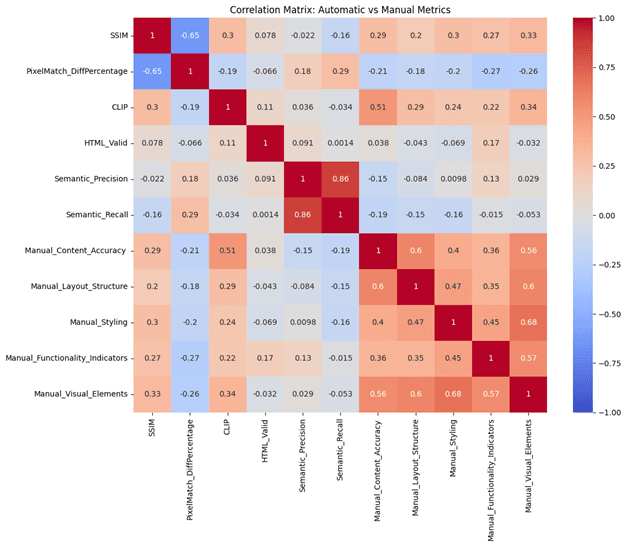
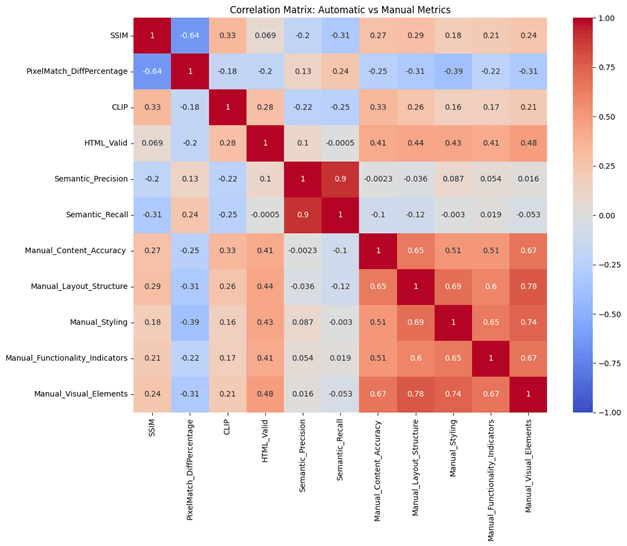
- •Developed comprehensive evaluation metrics combining automated and manual assessment
- •Implemented batch processing with checkpointing for large-scale testing
- •Created visualization tools for performance analysis using matplotlib and seaborn
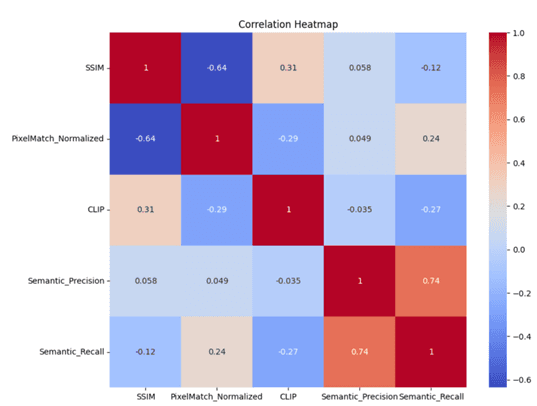
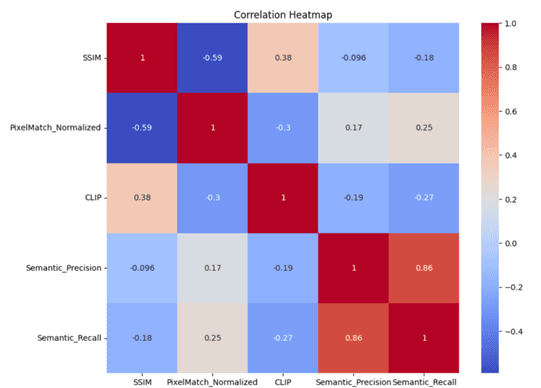
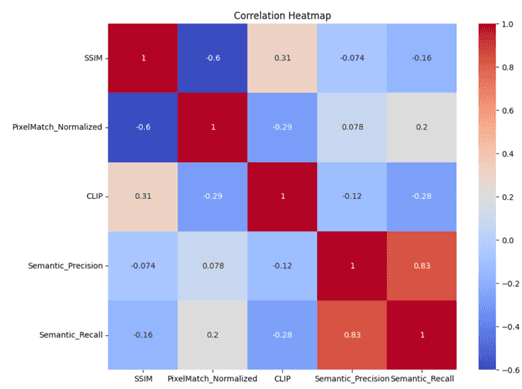
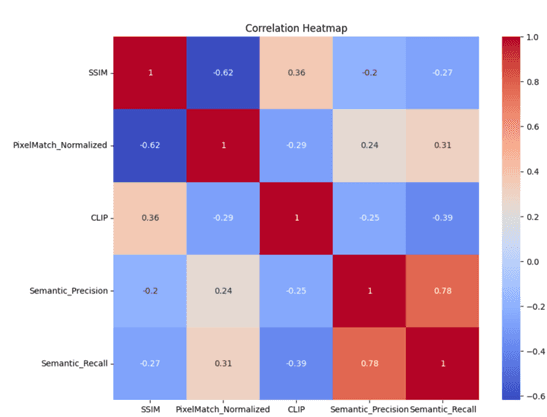
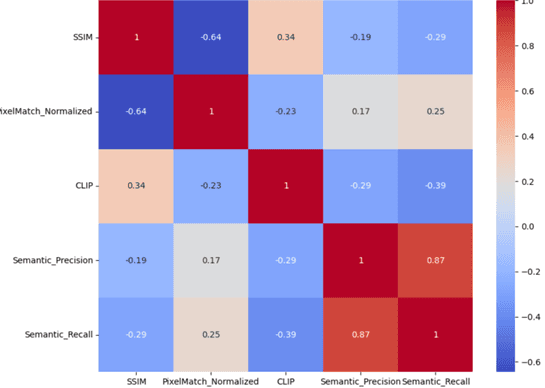
- •Built correlation analysis system for understanding relationships between different metrics
Key Findings
- •Claude 3.5 Sonnet achieved best overall performance with 97.6% HTML validity and high visual accuracy
- •GPT-4o demonstrated strong semantic understanding with 0.685 CLIP score
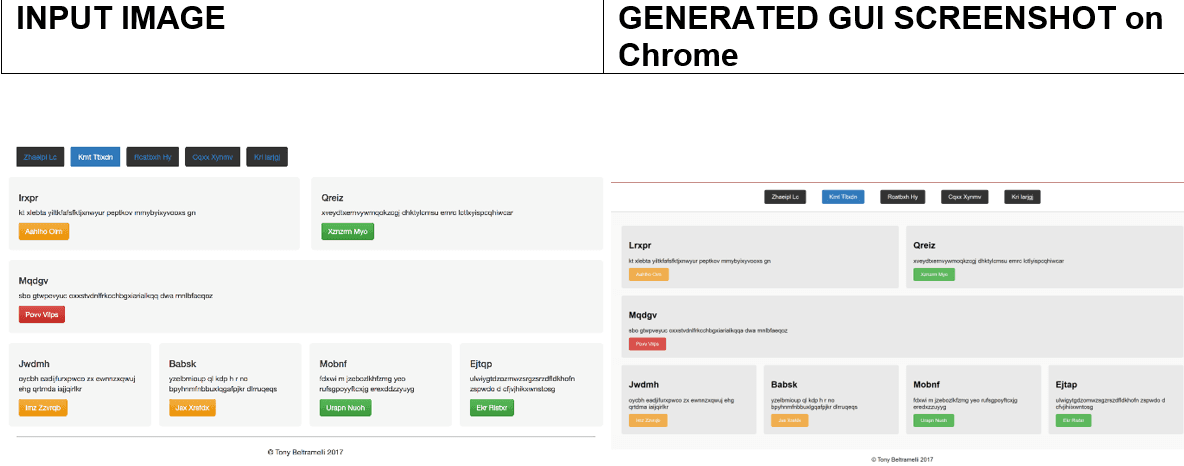
- •Gemini 1.5 Flash achieved highest visual accuracy with 24.26% PixelMatch Difference
- •Identified specific strengths and limitations of each model across different types of inputs
- •Discovered correlation patterns between automated metrics and human evaluation scores
The framework provides valuable insights into LLM capabilities in web development, revealing trade-offs between visual accuracy and code correctness. Results show that while current LLMs are promising for web GUI generation, they have specific strengths and limitations that developers should consider when choosing a model for their needs.
Technologies Used
Key Features
- •Automated testing pipeline for LLM evaluation
- •Multi-metric evaluation system
- •Cross-model performance comparison
- •Batch processing with checkpointing
- •Visual similarity assessment
- •HTML validation and accessibility checking
- •Correlation analysis tools
- •Performance visualization dashboard
- •Automated screenshot capture and comparison
Challenges Overcome
- •Handling large-scale image processing efficiently
- •Managing API rate limits and costs
- •Ensuring consistent evaluation across different LLMs
- •Developing reliable automated metrics
- •Balancing automated and manual evaluation methods